
Học tăng cường là gì? Lợi ích và thuật toán học tăng cường
Học tăng cường là gì là một khái niệm thu hút sự chú ý đặc biệt từ giới chuyên môn với việc đưa trí tuệ nhân tạo lên một tầm cao mới. Thuật ngữ này được ứng dụng rộng rãi trong robot hiện đại và nhiều lĩnh vực công nghiệp, y tế, và dịch vụ. Bài viết dưới đây sẽ giúp bạn tìm hiểu về khái niệm, ứng dụng và các thuật toán học tăng cường (Reinforcement Learning) sâu của lĩnh vực này.
Xem thêm:
- Cách sử dụng Gamma AI tạo slide thuyết trình tự động
- Cách sử dụng Gemini AI trên Google Bard để tìm thông tin
Học tăng cường là gì?
Học tăng cường (Reinforcement Learning - RL) là một lĩnh vực quan trọng của máy học, đặc biệt được áp dụng trong sản phẩm trí tuệ nhân tạo (AI), chơi game, và nhiều ứng dụng khác. RL bắt chước quy trình học thử và sai của con người để đào tạo phần mềm ra quyết định nhằm đạt được kết quả tối ưu.

Thay vì dựa vào dữ liệu giám sát, RL sử dụng phản hồi thông qua các khoản thưởng hoặc trừng phạt từ môi trường. Vậy thuật toán học tăng cường là gì? Thực chất, RL sử dụng các mô hình khen thưởng và trừng phạt để tự động điều chỉnh chiến lược dựa trên các phản hồi nhận được.Môi trường thường được mô tả bằng mô hình Markov Decision Process (MDP). Đây là nơi các trạng thái và hành động có thể được đánh giá trong ngữ cảnh xác suất. RL khác biệt so với học có giám sát bởi vì nó không yêu cầu cặp dữ liệu đầu vào/kết quả đúng. Thay vào đó, chúng tập trung vào việc tìm hiểu sự cân bằng giữa khám phá và khai thác trong việc tối ưu hóa.
Lợi ích của học tăng cường
Khi nói đến học tăng cường là gì, chúng ta không thể không nhấn mạnh về những lợi ích vượt trội mà nó mang lại. Trong bối cảnh phức tạp của trí tuệ nhân tạo và ứng dụng công nghiệp, RL đem đến những giải pháp sáng tạo và hiệu quả. Ba lợi ích chính từ RL có thể kể đến như sau:
Hoạt động hiệu quả trong những môi trường phức tạp
Một trong những lợi ích vượt trội nhất mà học tăng cường sâu mang lại là khả năng hoạt động hiệu quả trong những môi trường phức tạp và đa dạng. Dù có kiến thức rộng lớn về môi trường, con người cũng có thể gặp khó khăn trong việc xác định hướng đi tối ưu trong một môi trường phức tạp.

Trái lại, các thuật toán học tăng cường tự nhiên thích nghi và học hỏi từ môi trường một cách nhanh chóng. Nhờ đó, Reinforcement Learning có khả năng đáp ứng một cách chính xác và linh hoạt, giúp tối ưu hóa kết quả và hoạt động hiệu quả trong những môi trường đầy thách thức và không dự đoán được.
Tối ưu hóa kết quả trong dài hạn
Học tăng cường chủ yếu tập trung vào việc tối ưu hóa kết quả trong dài hạn. Trong thực tế, không phải lúc nào hành động của chúng ta cũng mang lại phản hồi ngay lập tức, và đó là nơi mà RL phát huy sức mạnh của mình.

Ví dụ, khi quản lý một hệ thống giao thông đô thị, RL có thể được áp dụng để tối ưu hóa hiệu suất của hệ thống giao thông, giúp giảm thiểu kẹt xe và tiết kiệm năng lượng.
Giảm thiểu công sức từ con người
Trong nhiều thuật toán máy học tiêu biểu, người dùng thường phải ghi nhãn hoặc chỉ dẫn dữ liệu để huấn luyện. Ngược lại, học tăng cường cho phép hệ thống tự học thông qua quá trình thử và sai, giảm bớt sự phụ thuộc vào sự can thiệp của con người.

Chưa hết, RL còn cung cấp khả năng tích hợp phản hồi từ con người, cho phép hệ thống điều chỉnh và tinh chỉnh theo sở thích, chuyên môn, và thông tin hiệu chỉnh từ người sử dụng.
Cách hoạt động của Reinforcement Learning
Nhìn chung, học tăng cường phản ánh một cơ chế học tập tự nhiên tồn tại trong sinh vật. Để hiểu cách RL hoạt động, chúng ta có thể nhìn vào cách con người và động vật học từ môi trường xung quanh.Giả sử một con chó trong một khu vườn thường xuyên tìm kiếm các hành động để đạt được mục tiêu là một đĩa thức ăn. Ban đầu, nó có thể cố gắng nhảy qua rào, chạy vòng quanh, hoặc kể cả đào bới để tìm đường vào. Mỗi hành động sẽ dẫn đến một kết quả: thành công hoặc thất bại.
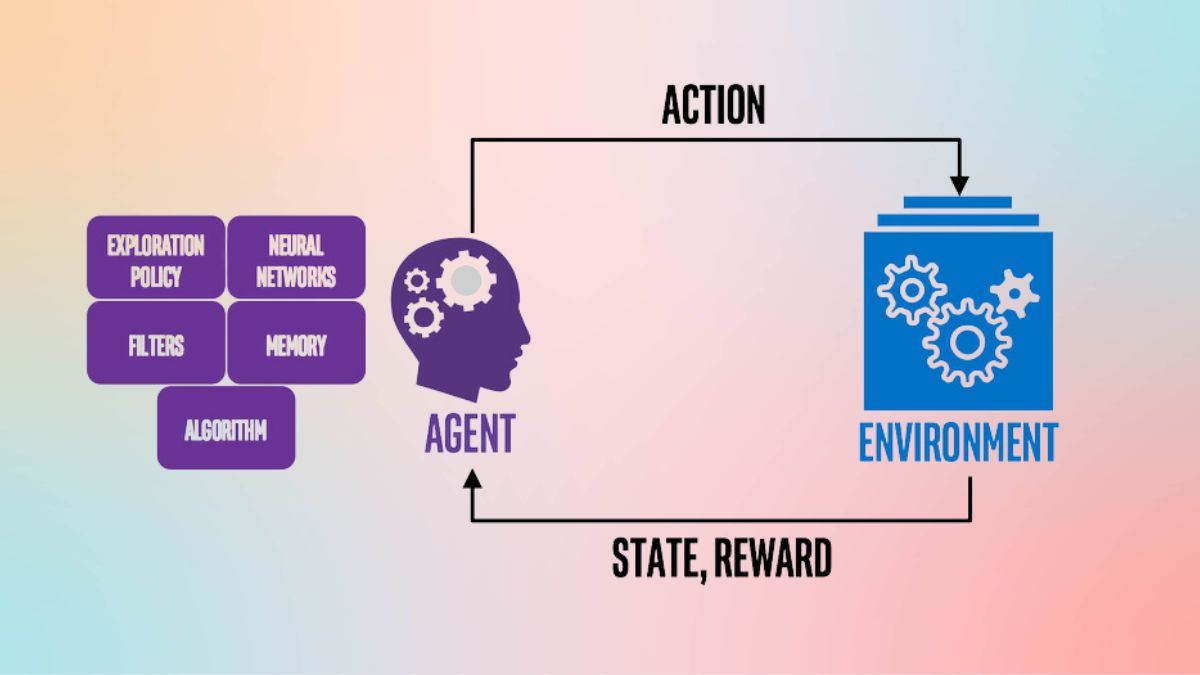
Trong các thuật toán học tăng cường sâu, cơ chế hoạt động cũng giống như vậy. Thuật toán sẽ thử nghiệm và khám phá các hành động khác nhau trong môi trường. Dựa trên phản hồi từ môi trường (thường được biểu diễn dưới dạng khen thưởng hoặc trừng phạt), RL sẽ cập nhật và điều chỉnh chiến lược hành động của mình.
Các thuật toán học tăng cường
Dù có vô số kỹ thuật, nhưng Reinforcement Learning có thể được phân loại vào hai hướng chính. Điều này đề cập đến cách mà các thuật toán RL xử lý và tối ưu hóa quyết định dựa trên phản hồi và môi trường.
Học tăng cường mô hình
RL dựa trên mô hình là một phương pháp trong lĩnh vực trí tuệ nhân tạo, được sử dụng khi môi trường quan sát có cấu trúc rõ ràng và ổn định. Trong quá trình này, tác tử tạo ra một mô hình nội bộ của môi trường dựa trên việc thực hiện hành động và ghi nhận phản hồi từ môi trường.

Quá trình này bắt đầu với việc tác tử thực hiện các hành động, ghi nhận các trạng thái mới và giá trị khen thưởng tương ứng. Sau đó, thông qua quá trình liên kết hành động và trạng thái, tác tử xây dựng một mô hình để dự đoán các kết quả từ hành động của mình.
Học tăng cường không mô hình
RL không mô hình là một phương pháp mạnh mẽ cho các môi trường mà không dễ dàng mô tả. Không giống như phương pháp dựa trên mô hình, tác tử trong RL không mô hình không cần phải tạo ra một bản đồ hoặc mô hình nội bộ của môi trường.

Thay vào đó, phương pháp này tập trung vào việc tương tác trực tiếp với môi trường, ghi nhận kết quả của các hành động và sử dụng kinh nghiệm đó để cập nhật và tinh chỉnh hành vi của mình.
Khi nào cần Reinforcement Learning?
Nhiều người phân vân học tăng cường là gì khi có thể được áp dụng trong nhiều trường hợp thực tế để tối ưu hóa trải nghiệm. Trong lĩnh vực tiếp thị, Reinforcement Learning có thể được sử dụng để tối ưu hóa gợi ý cho người dùng dựa trên tương tác của họ.
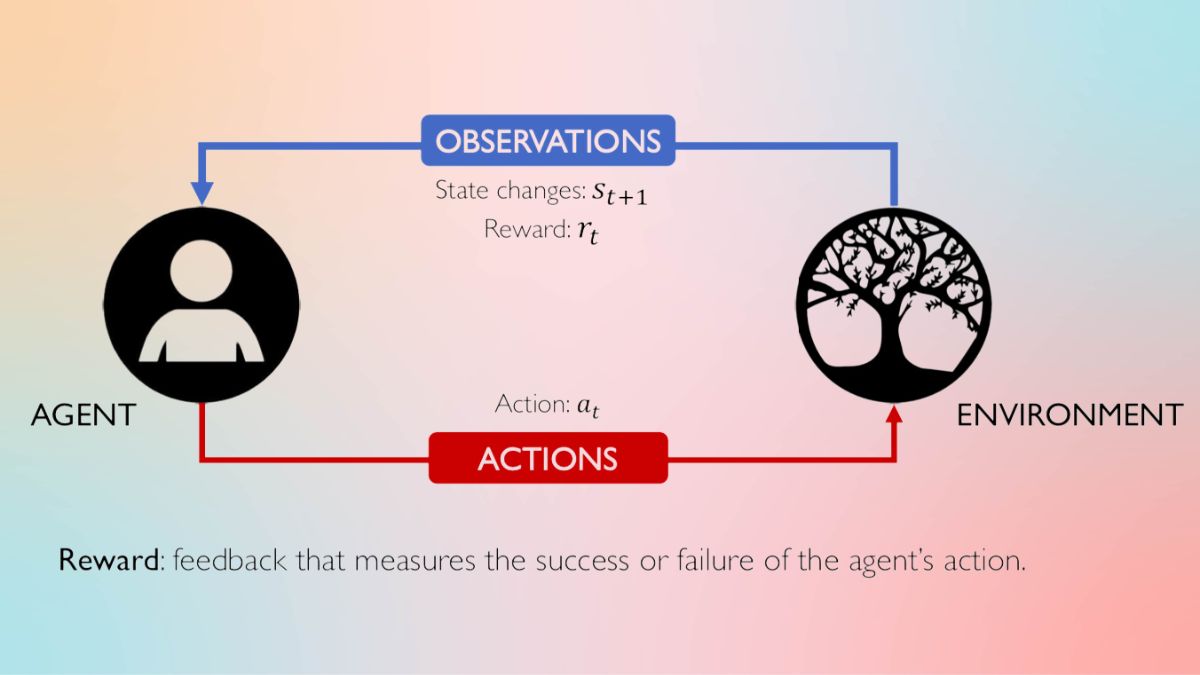
Ngoài ra, RL có thể vượt trội trong các thách thức tối ưu hóa khi môi trường thay đổi và không dễ dàng mô hình hóa. Trong việc quản lý tài nguyên đám mây, RL có thể tối ưu hóa chi phí và sử dụng tài nguyên dựa trên nhu cầu biến động.Trong môi trường động của thị trường tài chính, các thuật toán học tăng cường sâu có thể linh hoạt dự đoán và tối ưu hóa lợi nhuận dài hạn. Họ có thể điều chỉnh chiến lược đầu tư dựa trên sự biến động của thị trường và các yếu tố chi phí, tạo ra quyết định thông minh trong môi trường tài chính không dự đoán được.
Học tăng cường có gì khác học có giám sát và không có giám sát
Trong lĩnh vực trí tuệ nhân tạo, máy học chia thành ba hình thức chính: học có giám sát, học không có giám sát và học tăng cường (RL). Mặc dù chúng đều nhằm mục tiêu học từ dữ liệu, từng loại thuật toán này lại có cách tiếp cận và ứng dụng riêng biệt.
Học tăng cường với học có giám sát
Trong học có giám sát, chúng ta có một tập dữ liệu đã được gắn nhãn, và mục tiêu là dự đoán đầu ra dựa trên đầu vào dựa trên các khuôn mẫu đã biết.Trong khi đó, Reinforcement Learning không cần sự can thiệp đó. Thay vào đó, nó tập trung vào việc đưa ra quyết định tối ưu trong một môi trường dựa trên phản hồi. Trong quá trình đào tạo, RL khám phá các hành động và kết quả tốt nhất thông qua việc thử nghiệm và lỗi.

Ví dụ, trong môi trường chơi game, RL có thể tự học cách di chuyển và tương tác với môi trường mà không cần biết trước đầu ra mong muốn.
Học tăng cường với học không có giám sát
Trong học không có giám sát, các thuật toán RL đối mặt với dữ liệu đầu vào không có đầu ra cụ thể được chỉ định. Thay vào đó, nó dựa vào các phương pháp thống kê để tìm ra các mô hình ẩn và phân loại dữ liệu. Mặc dù kết quả thu được có thể không cụ thể, nó cung cấp cái nhìn tổng quan và phân loại chung của dữ liệu.

Trong khi đó, RL đặt ra một mục tiêu rõ ràng và tập trung vào việc tối ưu hóa hành động để đạt được mục tiêu này. Mặc dù có thể sử dụng cách tiếp cận thăm dò, RL liên tục cải tiến các hành vi dựa trên phản hồi để tối ưu hóa mục tiêu cuối. RL có thể tự đào tạo và tìm hiểu các chiến lược cụ thể để đạt được kết quả mong muốn một cách hiệu quả.
Tạm kết
Trên đây là toàn bộ thông tin về học tăng cường là gì, các thuật toán học tăng cường (Reinforcement Learning) sâu chi tiết. Hy vọng thông tin trên có thể giúp bạn hiểu rõ hơn về phương pháp trong lĩnh vực máy học này.
- Xem thêm bài viết chuyên mục: Thuật ngữ công nghệ, AI







Bình luận (0)